ElasticSearch 기본용어.

클러스터
- 클러스터는 하나 또는 여러 노드들의 집합
- 클러스터 이름을 기준으로 노드들이 묶임
- 데이터를 노드들이 나눠 갖으며 노드들끼리 연합하여 인덱싱과 검색 작업 수행.
Node
- 단일 서버이며 클러스터의 구성원.
- 데이터를 저장하고 클러스터의 인덱싱과 검색 작업에 참여함
- 클러스터처럼 노드도 이름으로 식별
- 클러스터에 노드가 추가되면 샤드가 재분배된다.
- Data 노드
- 데이터가 저장되는 노드
- 인덱싱 및 검색 작업 수행
- transport 모듈로 통신하기 때문에 http 모듈은 비활성화.
- Non-Data 노드
- 마스터 전용 노드
- 클러스터-노드-샤드의 맵핑 정보를 담고있는 노드
- 클러스터 관리 명령 수행하는 노드.
- 중요한 클러스터라면 마스터 전용 노드가 3개는 존재하도록 설정을 권장
- discovery.zen.minimum_master_nodes : (「node.master: true」인 노드 개수 / 2 ) + 1
- 클라이언트 노드
- 노드들의 앞단에서 로드 밸런서 역할
- HTTP 쿼리 파싱, 검색 요청에대한 set/get, 네트워크 부하 담당.
- 데이터 저장, 클러스터 관리 명령은 하지 않는다.
- 마스터 전용 노드
Index
- 도큐먼트의 집합
- RDB의 Table와 비슷하다.
Document
- 인덱스 가능한 정보의 기본 단위
- JSON으로 표현된다.
- ROW를 나타낸다.
Property
- 도큐먼트의 값들의 구성요소
- col을 나타낸다.
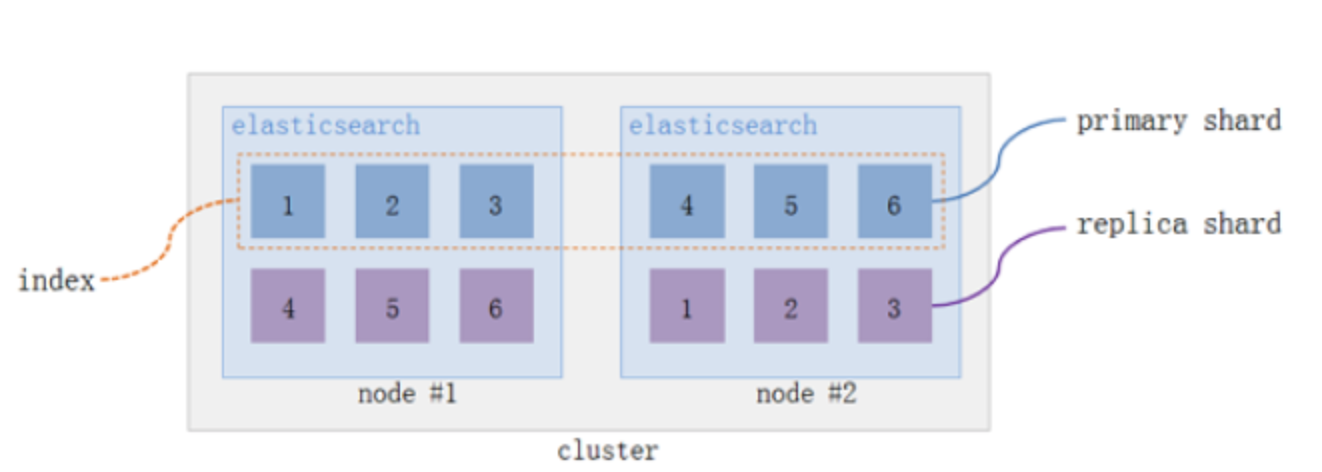
shard란?
데이터를 저장할 때 나누어진 하나의 조각에 대한 단위이다.
shard는 데이터에 대한 복사본이 아니라 데이터 그 자체이다.
가장 먼저 1copy씩 존재하는 데이터 shard를 primary shard라고 합니다.
- 하나의 인덱스는 단일 노드의 용량을 초과할만큼 대량의 데이터 저장 가능
- 인덱스를 관리하면 단일 노드로 용량 및 검색 속도의 한계 존재
- 인덱스를 여러 조각(샤드)으로 나눠서 한계를 극복
- 샤딩을 통해 볼륨을 분할/확장 가능
- 샤딩을 통해 샤드끼리 분산/병렬 처리 가능 → 성능 향상
- 샤드의 개수는 인덱스를 생성할 때 지정 가능
- 인덱스를 생성할 때 샤드 개수 지정. 이후로는 변경 불가. (기본값 : 5)
Replica란?
primary shard와 동일한 복제본의 개수를 나타낸다.
Replica가 필요한 이유.
- 검색성능
- 장애복구
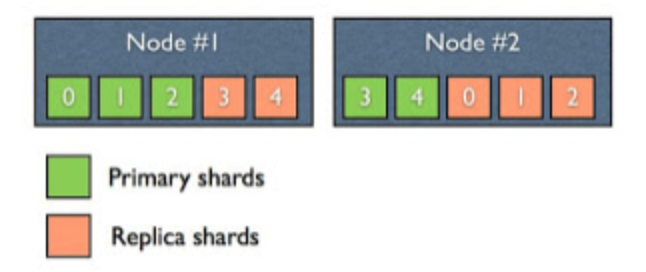
Replica는 primary shard랑 같은 노드상에 존재할 수 없다.
- 리플리카 샤드, 줄여서 리플리카라고 부르기도 함
- 샤드 또는 노드가 장애를 일으키는 경우를 대비하여 하나 이상의 복사본(리플리카 샤드)을 생성
- 높은 가용성 제공을 위해 리플리카는 원본(프라이머리 샤드)과 다른 노드에 존재
- 검색은 모든 리플리카에서 병렬로 실행가능 → 검색 성능 수평 확장(scale out) 가능
- 인덱스를 생성할 때 리플리카 개수 지정. 이후로도 동적으로 변경 가능 (기본값 : 1)
- 리플리카를 2로 설정하면 샤드가 5개일 때 리플리카 샤드는 총 10개가 생성됨